











जब वास्तुकार डेटा मॉडल डिज़ाइन करते हैं, तो प्रतिनिधित्व संबंध आरेख (ERD) आधारभूत नक्शा के रूप में कार्य करता है। यह केवल तालिकाओं और स्तंभों का दृश्य प्रतिनिधित्व नहीं है; यह संबंधों, अखंडता और प्रवाह की विशिष्टता है। इस संरचना के सबसे महत्वपूर्ण घटकों में विदेशी कुंजियाँ शामिल हैं। जबकि इन्हें अक्सर केवल डेटा अखंडता से जोड़ा जाता है, उनका प्रभाव प्रदर्शन मापदंडों, स्टोरेज की कुशलता और प्रश्न निष्पादन गति तक गहराई से फैलता है।
इस विश्लेषण में प्रतिनिधित्व संबंध आरेख (ERD) प्रदर्शन के संदर्भ में विदेशी कुंजियों के तकनीकी तंत्र का अध्ययन किया जाएगा। हम इन सीमाओं के इंडेक्सिंग रणनीतियों, लॉकिंग तंत्र और डेटाबेस स्कीमा की समग्र विस्तारशीलता पर कैसे प्रभाव डालते हैं, इसका अध्ययन करेंगे। लक्ष्य भौतिक मॉडल में संबंधों को परिभाषित करते समय शामिल व्यापार बाधाओं को स्पष्ट रूप से समझने में मदद करना है।
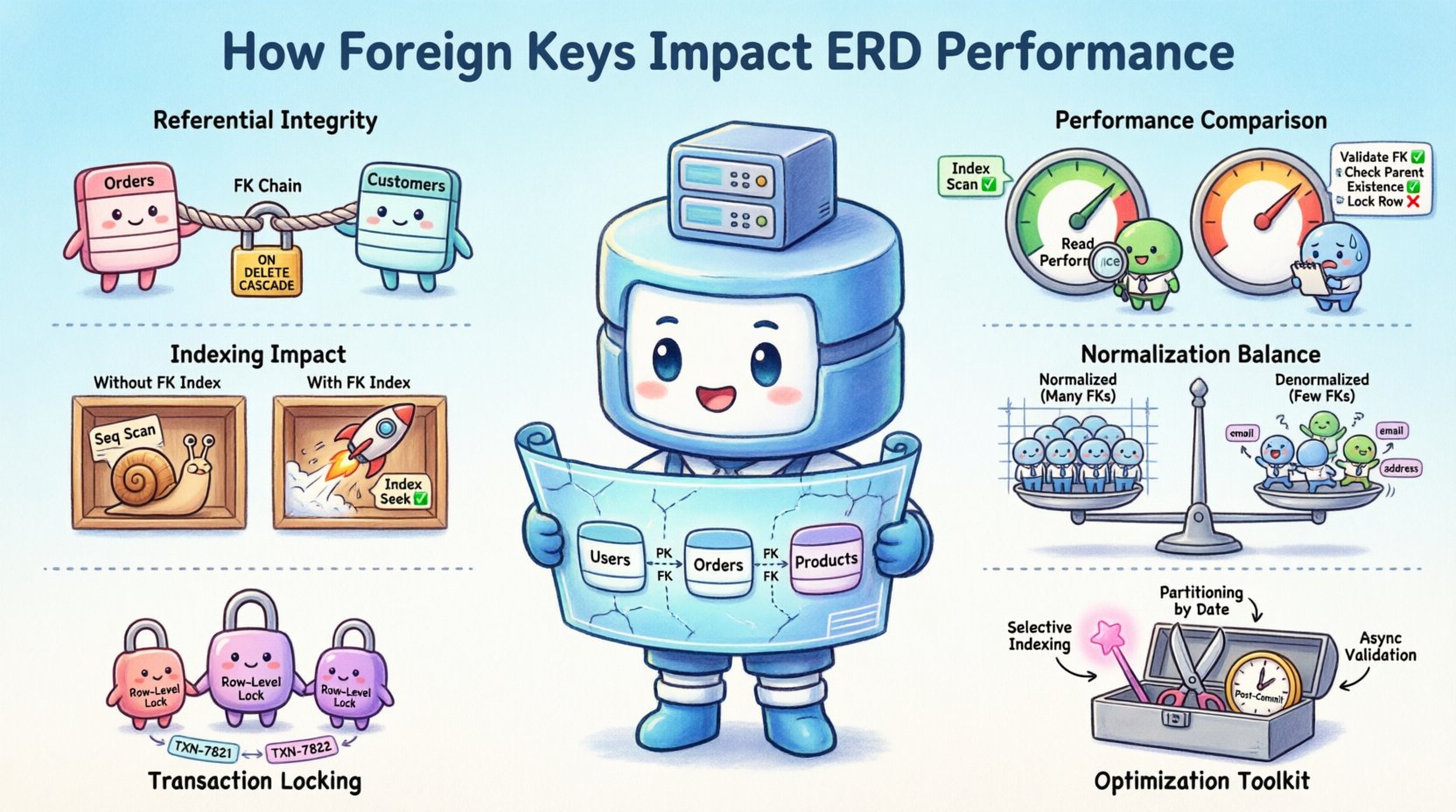
विदेशी कुंजियों के मूल कार्य को समझना ⚙️
एक विदेशी कुंजी एक सीमा है जो एक तालिका के स्तंभ को दूसरी तालिका की प्राथमिक कुंजी से जोड़ती है। इस जुड़ाव के द्वारा संदर्भात्मक अखंडता बनाए रखी जाती है, जिससे यह सुनिश्चित होता है कि बच्चे की तालिका में एक रिकॉर्ड माता-पिता तालिका में मौजूद एक रिकॉर्ड से मेल खाता है। हालांकि, इस सीमा के कार्यान्वयन के साथ गणनात्मक लागत भी आती है।
प्रदर्शन के दृष्टिकोण से, विदेशी कुंजी डेटाबेस इंजन के लिए एक संकेत के रूप में कार्य करती है। यह प्रश्न योजनाकर्ता को संबंध के अस्तित्व के बारे में बताती है, जो जॉइन एल्गोरिदम को प्रभावित कर सकता है। लेकिन यह डेटा संशोधन के दौरान अतिरिक्त भार भी डालती है।
- इन्सर्ट ऑपरेशन: जब एक नई पंक्ति बच्चे की तालिका में जोड़ी जाती है, तो इंजन को यह सत्यापित करना होता है कि संदर्भित माता-पिता की कुंजी मौजूद है।
- डिलीट ऑपरेशन: माता-पिता तालिका से एक पंक्ति हटाने के लिए निर्भर बच्चे की रिकॉर्ड्स पर कैस्केडिंग अपडेट या जांच करने की आवश्यकता हो सकती है।
- अपडेट ऑपरेशन: माता-पिता तालिका में प्राथमिक कुंजी बदलने के लिए बच्चे की तालिकाओं में प्रत्येक विदेशी कुंजी संदर्भ को अपडेट करना आवश्यक होता है।
इन जांचों को तुरंत नहीं किया जाता है। दो लेन-देन एक साथ संबंधित डेटा को संशोधित करने की कोशिश करने वाली दौड़ स्थितियों को रोकने के लिए लॉकिंग तंत्र की आवश्यकता होती है। इस प्रकार, ERD में विदेशी कुंजियों के घनत्व का लेन-देन प्रबंधन की जटिलता से सीधा संबंध होता है।
प्रदर्शन मापदंड: पढ़ना बनाम लिखने के कार्यभार 📊
डेटाबेस प्रदर्शन अक्सर सभी संचालनों में समान नहीं होता है। विदेशी कुंजियाँ पढ़ने और लिखने के कार्यभार को अलग-अलग तरीके से प्रभावित करती हैं। इस अंतर को समझना स्कीमा डिज़ाइन को ट्यून करने के लिए निर्णायक है।
1. पढ़ने का प्रदर्शन (प्रश्न निष्पादन)
जब एक प्रश्न दो तालिकाओं के जॉइन को शामिल करता है, तो विदेशी कुंजी संबंध की उपस्थिति ऑप्टिमाइज़र की सहायता कर सकती है। यदि सांख्यिकी बनाए रखी जाती हैं, तो इंजन जॉइन की कार्डिनैलिटी का अनुमान अधिक सटीक रूप से लगा सकता है। इससे अक्सर बेहतर निष्पादन योजनाएं बनती हैं।
- जॉइन अनुकूलन: प्रश्न योजनाकर्ता ज्ञात कार्डिनैलिटी सीमाओं के आधार पर हैश जॉइन या मर्ज जॉइन चुन सकता है।
- इंडेक्स उपयोग: विदेशी कुंजियाँ अक्सर बच्चे की तालिका के स्तंभों पर इंडेक्स बनाने के लिए प्रेरित करती हैं। इन इंडेक्सेस जॉइन के दौरान खोज को तेज करते हैं।
- कैश कुशलता: सही तरीके से इंडेक्स की गई विदेशी कुंजियाँ मेमोरी से अधिक कुशल पृष्ठ पढ़ने की अनुमति देती हैं, जिससे डिस्क I/O कम होता है।
2. लिखने का प्रदर्शन (डेटा संशोधन)
लिखने के दौरान विदेशी कुंजियाँ महत्वपूर्ण देरी लाती हैं। प्रत्येक इन्सर्ट या अपडेट को सीमा की पुष्टि करनी होती है।
- लुकअप ओवरहेड: प्रणाली को माता-पिता तालिका के इंडेक्स में खोज करनी होती है ताकि यह सुनिश्चित किया जा सके कि कुंजी मौजूद है। इससे प्रत्येक लिखने में एक पढ़ने का ऑपरेशन जोड़ दिया जाता है।
- कैस्केडिंग लागतें: यदि कैस्केडिंग डिलीट या अपडेट सक्षम हैं, तो माता-पिता रिकॉर्ड पर एक ही क्रिया कई बच्चे की तालिकाओं में अपडेट ट्रिगर कर सकती है।
- लॉकिंग प्रतिस्पर्धा: विदेशी कुंजियाँ पंक्तियों के बीच निर्भरता बनाती हैं। यदि दो लेनदेन एक ही मुख्य पंक्ति में डालने की कोशिश करते हैं, तो वे एक दूसरे को ब्लॉक कर सकते हैं, जब तक अखंडता जांच पूरी नहीं हो जाती।
इंडेक्सिंग संबंध 🔗
सबसे आम गलतफहमियों में से एक यह है कि विदेशी कुंजियाँ स्वचालित रूप से इंडेक्स बनाती हैं। बहुत से डेटाबेस इंजनों में, यह डिफ़ॉल्ट व्यवहार नहीं है। हालांकि, बच्चे के कॉलम पर इंडेक्स के बिना विदेशी कुंजी पर भरोसा करना एक प्रदर्शन की बाधा है।
विदेशी कुंजी कॉलम पर इंडेक्स के बिना:
- इन्सर्ट के दौरान मुख्य कुंजी के अस्तित्व की पुष्टि करने के लिए डेटाबेस को पूरी टेबल स्कैन करना होगा।
- मुख्य और बच्चे की टेबल के बीच जॉइन ऑपरेशन बहुत धीमे होंगे, जो अक्सर नेस्टेड लूप जॉइन के लिए वापस जाते हैं।
- जैसे-जैसे डेटासेट बढ़ता है, संदर्भात्मक अखंडता जांच महंगी हो जाती है।
विपरीत रूप से, विदेशी कुंजी कॉलम पर इंडेक्स जोड़ने से इन समस्याओं का समाधान होता है, लेकिन इसमें अपनी खुद की लागत भी आती है:
- स्टोरेज ओवरहेड: प्रत्येक इंडेक्स डिस्क स्पेस और मेमोरी का उपयोग करता है।
- लेखन धीमा होना: हर बार एक पंक्ति को डाला, अपडेट किया या हटाया जाता है, तो इंडेक्स को संशोधित किया जाना चाहिए।
- फ्रैगमेंटेशन: समय के साथ, इंडेक्स फ्रैगमेंटेड हो सकते हैं, जिसके लिए रखरखाव कार्यों की आवश्यकता होती है।
तालिका: विदेशी कुंजी इंडेक्सिंग प्रभाव
| कारक | विदेशी कुंजी इंडेक्स के बिना | विदेशी कुंजी इंडेक्स के साथ |
|---|---|---|
| इन्सर्ट गति | धीमी (पूर्ण स्कैन जांच) | तेज (इंडेक्स खोज) |
| जॉइन गति | धीमी (नेस्टेड लूप्स) | तेज (हैश/मर्ज जॉइन) |
| स्टोरेज उपयोग | कम | अधिक |
| अपडेट ओवरहेड | कम | उच्च (इंडेक्स रखरखाव) |
ERD दृश्यावलोकन और जटिलता 🎨
एक ERD डेवलपर्स, आर्किटेक्ट्स और स्टेकहोल्डर्स के बीच संचार का एक उपकरण है। विदेशी कुंजियों की घनत्व आरेख की पठनीयता को प्रभावित करता है। अत्यधिक संबंधों से भरे आरेख में मूल डेटा प्रवाह छिप सकता है।
1. दृश्य अव्यवस्था
जब किसी एकता में बहुत सारी आउटगोइंग या इनगोइंग विदेशी कुंजियाँ होती हैं, तो उन्हें जोड़ने वाली रेखाएँ एक ‘स्पैगेटी आरेख’ प्रभाव बनाती हैं। इससे किसी विशिष्ट एकता के मूल निर्भरताओं को समझना या डेटा लाइनेज का पता लगाना मुश्किल हो जाता है।
- रेखा क्रॉसिंग्स: अत्यधिक संबंध रेखाओं को प्रतिच्छेद करते हैं, जिससे स्पष्टता कम हो जाती है।
- नोड का आकार: उच्च संबंध संख्या वाली एकताएँ बड़े बाउंडिंग बॉक्स की आवश्यकता करती हैं, जिससे लेआउट की सममिति बिगड़ जाती है।
- व्याख्या समय: इंजीनियर्स मॉडल को समझने में अधिक समय बिताते हैं, बजाय तर्क को लागू करने के।
2. तार्किक बनाम भौतिक मॉडल
अक्सर तार्किक ERD और भौतिक स्कीमा के बीच अंतर करना आवश्यक होता है। तार्किक मॉडल व्यापार नियमों और संबंधों पर ध्यान केंद्रित करता है। भौतिक मॉडल प्रदर्शन और कार्यान्वयन पर ध्यान केंद्रित करता है।
- तार्किक स्तर:सभी संबंधों का प्रतिनिधित्व करना चाहिए ताकि व्यापार नियमों को पकड़ा जा सके।
- भौतिक स्तर:कुछ संबंधों को हटा दिया जा सकता है या अनामानवीकृत किया जा सकता है ताकि प्रश्न गति में सुधार हो।
इस अंतर के कारण ERD एक वैध व्यापार दस्तावेज बना रहता है, जबकि आधारभूत डेटाबेस विशिष्ट वर्कलोड पैटर्न के लिए अनुकूलित किया जाता है।
नॉर्मलाइजेशन और विदेशी कुंजी संतुलन ⚖️
एक डेटाबेस को नॉर्मलाइज करने का निर्णय विदेशी कुंजियों को शामिल करने के साथ जुड़ा होता है। नॉर्मलाइजेशन अतिरिक्तता को कम करता है और डेटा सुसंगतता सुनिश्चित करता है। हालांकि, इससे डेटा प्राप्त करने के लिए आवश्यक जॉइन्स की संख्या बढ़ जाती है।
तृतीय सामान्य रूप (3NF)
3NF में, प्रत्येक गैर-कुंजी विशेषता पूर्ण कुंजी पर निर्भर होती है। इससे बहुत सारी तालिकाओं और बहुत सारी विदेशी कुंजियों वाला स्कीमा बनता है।
- लाभ:न्यूनतम डेटा दोहराव, सुसंगत अद्यतन, टेक्स्ट फील्ड्स के लिए कम भंडारण।
- नुकसान:बहुत सारे जॉइन्स की आवश्यकता वाले जटिल प्रश्न, पढ़ने पर अधिक निर्भर प्रणालियों में संभावित प्रदर्शन में गिरावट।
अनामानवीकरण रणनीतियाँ
उच्च प्रदर्शन वाली रिपोर्टिंग या पढ़ने पर अधिक निर्भर एप्लिकेशन के लिए, अनामानवीकरण एक व्यवहार्य रणनीति है। इसमें विदेशी कुंजियों को हटाना और डेटा की प्रतिलिपि बनाना शामिल होता है।
- मैटेरियलाइज्ड दृश्य:तालिकाओं के रूप में संग्रहीत पूर्व-गणना किए गए परिणाम जॉइन्स की आवश्यकता को कम करते हैं।
- आवर्धित स्तंभ: लेनदेन तालिका में एक श्रेणी के नाम को सीधे संग्रहीत करने से श्रेणी तालिका में जॉइन करने की आवश्यकता नहीं होती है।
- ट्रेडऑफ: आप लेखन प्रदर्शन को त्यागते हैं और रीड स्पीड प्राप्त करने के लिए भंडारण बढ़ाते हैं।
तालिका: सामान्यीकरण बनाम प्रदर्शन
| पहलू | सामान्यीकृत (बहुत सारे एफकेएस) | असामान्यीकृत (कम एफकेएस) |
|---|---|---|
| डेटा अखंडता | उच्च (एफके� द्वारा बलपूर्वक लागू) | निम्न (हाथ से जांच की आवश्यकता होती है) |
| प्रश्न जटिलता | उच्च (बहुगुणा जॉइन) | निम्न (एकल तालिका) |
| लेखन गति | तेज (कम अतिरिक्तता) | धीमी (सभी प्रतियों को अपडेट करना) |
| पढ़ने की गति | धीमी | तेज |
समानांतरता और लॉकिंग तंत्र 🔒
विदेशी कुंजियाँ कुछ डेटाबेस इंजनों में प्रीडिकेट लॉकिंग या गैप लॉकिंग के रूप में जानी जाने वाली एक विशिष्ट लॉकिंग व्यवहार पेश करती हैं। जब कोई लेनदेन एक पंक्ति को बदलता है जिसका विदेशी कुंजी द्वारा संदर्भित किया गया है, तो वह केवल बदली जा रही पंक्ति को लॉक करने के अलावा, संभवतः मातृ पंक्ति को भी लॉक करना होगा।
1. मृत अवरोध
बहुत सारी विदेशी कुंजियों वाले अत्यधिक जुड़े हुए स्कीमा मृत अवरोध के प्रति संवेदनशील होते हैं। यह तब होता है जब दो लेनदेन एक दूसरे की आवश्यकता वाले संसाधनों पर लॉक रखते हैं।
- परिदृश्य: लेनदेन A मातृ तालिका X को अपडेट करता है। लेनदेन B तालिका Y को अपडेट करता है जो X को संदर्भित करती है।
- संघर्ष: यदि दोनों लेनदेन अलग-अलग क्रम में एक दूसरे के संसाधन को लॉक करने की कोशिश करते हैं, तो प्रणाली दोनों को रोक देती है।
2. विस्तार
डेटाबेस इंजन अक्सर पंक्ति स्तर पर लॉक करते हैं। हालांकि, विदेशी कुंजी सीमाएँ सूचकांक स्तर पर लॉक करने के लिए मजबूर कर सकती हैं। यदि एक सूचकांक का स्कैन किया जाता है विदेशी कुंजी की पुष्टि करने के लिए, तो पूरे सूचकांक के रेंज को लॉक कर दिया जा सकता है।
- प्रभाव: उच्च समानांतरता वाले प्रणाली में विदेशी कुंजी जांच अन्य लेन-देन को ब्लॉक कर सकती है, जिससे निर्गमन दर कम हो सकती है।
- निवारण: लेन-देन के ध्यान से क्रम और अनुरोध पैटर्न के अनुरूप इंडेक्स सुनिश्चित करने से प्रतिस्पर्धा कम हो सकती है।
स्टोरेज ओवरहेड और मेमोरी फुटप्रिंट 💾
प्रत्येक विदेशी कुंजी कॉलम स्टोरेज का उपयोग करता है। एकल पूर्णांक या UUID छोटा लग सकता है, लेकिन बिलियनों रिकॉर्ड वाली प्रणाली में यह संचयी हो जाता है।
1. डेटा प्रकार और संरेखण
विदेशी कुंजी के डेटा प्रकार को प्राथमिक कुंजी के साथ मेल खाना चाहिए। यदि प्राथमिक कुंजी एक संयुक्त कुंजी (बहुल कॉलम) है, तो विदेशी कुंजी भी संयुक्त होनी चाहिए।
- संयुक्त कुंजियाँ: इनके इंडेक्स का आकार महत्वपूर्ण रूप से बढ़ जाता है। एक संयुक्त विदेशी कुंजी इंडेक्स एकल कॉलम इंडेक्स की तुलना में बहुत बड़ा हो सकता है।
- नलता: यदि विदेशी कुंजी नल की अनुमति देती है, तो स्टोरेज इंजन को नल बिटमैप का प्रबंधन करना होगा, जिससे थोड़ा अतिरिक्त ओवरहेड आता है।
2. मेमोरी उपयोग
प्रश्न के निष्पादन के दौरान इंडेक्स मेमोरी में रहते हैं। बड़ी संख्या में विदेशी कुंजियाँ और उनके संबंधित इंडेक्स उपलब्ध बफर पूल मेमोरी को खत्म कर सकते हैं।
- कैश प्रदूषण: अक्सर एक्सेस किए जाने वाले डेटा को मेमोरी से बाहर धकेल दिया जाता है ताकि इंडेक्स संरचनाओं के लिए जगह बनाई जा सके।
- स्वैप उपयोग: यदि मेमोरी पर्याप्त नहीं है, तो प्रणाली डिस्क पर स्वैप कर सकती है, जिससे प्रदर्शन बहुत धीमा हो जाता है।
ERD प्रदर्शन के लिए अनुकूलन रणनीतियाँ 🚀
अखंडता और गति के बीच स्वस्थ संतुलन बनाए रखने के लिए डिज़ाइन चरण के दौरान विशिष्ट रणनीतियाँ लागू करनी चाहिए।
1. चयनात्मक इंडेक्सिंग
हर विदेशी कुंजी को अनजाने में इंडेक्स न करें। प्रश्न पैटर्न का विश्लेषण करें।
- उच्च आवृत्ति जॉइन्स: यदि दो तालिकाओं को अक्सर जोड़ा जाता है, तो विदेशी कुंजी को इंडेक्स करें।
- दुर्लभ संबंध: यदि कोई संबंध दुर्लभ रूप से प्रश्न किया जाता है, तो इंडेक्स ओवरहेड लाभ से अधिक हो सकता है।
2. पार्टीशनिंग
बड़ी तालिकाओं को पार्टीशन करने से विदेशी कुंजी जांच को विशिष्ट डेटा सेगमेंट्स तक सीमित किया जा सकता है।
- रेंज पार्टीशनिंग: डेटा को तारीख या आईडी रेंज के आधार पर विभाजित करें।
- प्रभाव: अखंडता जांच के दौरान स्कैन किए जाने वाले इंडेक्स के आकार को कम करता है।
3. असिंक्रोनस सत्यापन
कुछ उच्च थ्रूपुट सिस्टम में, सख्त संदर्भात्मक अखंडता को असिंक्रोनस तरीके से लागू किया जाता है।
- प्रक्रिया: डेटा को तुरंत एफके जांच के बिना सम्मिलित किया जाता है।
- सफाई: एक बैकग्राउंड कार्य नियमित रूप से अनाथ रिकॉर्ड्स की जांच करता है और उन्हें साफ करता है।
- लाभ: अस्थायी डेटा असंगति के लागत पर लेखन प्रदर्शन को बहुत बेहतर बनाता है।
बचने वाले सामान्य त्रुटियाँ ⚠️
भारी विदेशी कुंजी उपयोग के साथ ईआरडी डिज़ाइन करते समय अनुभवी वास्तुकार भी जाल में फंस सकते हैं।
- श्रृंखलाबद्ध संबंध: लंबी विदेशी कुंजी श्रृंखलाएँ (ए → बी → सी → डी) प्रश्नों को गहरा और अनुकूलित करने में कठिन बना देती हैं।
- स्वयं-संदर्भित कुंजियाँ: एक तालिका जो स्वयं को संदर्भित करती है (उदाहरण के लिए, कर्मचारी → प्रबंधक) रिकर्सिव प्रश्नों और इंडेक्सिंग रणनीतियों को जटिल बना सकती है।
- चौड़ी प्राथमिक कुंजियाँ: बहु-स्तंभ प्राथमिक कुंजी का उपयोग करने से विदेशी कुंजी को चौड़ा होना पड़ता है, जिससे सभी बच्चे के इंडेक्स बढ़ जाते हैं।
- सांख्यिकी के बारे में ध्यान न देना: यदि डेटाबेस इंजन को विदेशी कुंजी स्तंभों पर ताजा सांख्यिकी की कमी है, तो प्रश्न योजक खराब निष्पादन योजनाएँ चुन सकता है।
अपने स्कीमा को भविष्य के लिए सुरक्षित बनाना 🔮
वर्तमान प्रदर्शन के लिए डिज़ाइन करना आवश्यक है, लेकिन स्केलेबिलिटी के लिए भविष्य की योजना बनाना आवश्यक है। जैसे-जैसे डेटा का आकार घातीय रूप से बढ़ता है, विदेशी कुंजियाँ बॉटलनेक बन सकती हैं।
1. क्षैतिज स्केलिंग
जब एक वितरित डेटाबेस में जाया जाता है, तो विदेशी कुंजी प्रतिबंध कठिन हो जाते हैं।
- शार्डिंग: शार्ड्स के बीच फैली विदेशी कुंजियाँ केंद्रीय समन्वय के बिना बनाए रखने में कठिन होती हैं।
- संगतता: विदेशी कुंजी निर्भरता वाले नोड्स के बीच एसीआईडी गुणों को बनाए रखने के लिए जटिल प्रोटोकॉल की आवश्यकता होती है।
2. स्कीमा विकास
आवश्यकताओं में परिवर्तन होने पर, संबंधों को बदलने की आवश्यकता हो सकती है।
- कुंजियों को बदलना:एक बड़ी टेबल पर विदेशी कुंजी प्रतिबंध को बदलने से टेबल को लंबे समय तक लॉक कर दिया जा सकता है।
- माइग्रेशन:स्कीमा माइग्रेशन के लिए उपयोग किए जाने वाले टूल्स को विदेशी कुंजी निर्भरता को संभालना चाहिए ताकि उत्पादन डेटा बिगड़ने से बचा जा सके।
मुख्य विचारों का सारांश 📝
ERD में विदेशी कुंजियों को शामिल करने का निर्णय द्विआधारी नहीं है। यह अखंडता की आवश्यकताओं के प्रदर्शन लागत के विपरीत गणना है।
- अखंडता:विदेशी कुंजियाँ डेटा नियमों को स्वचालित रूप से लागू करने का प्राथमिक तंत्र हैं।
- प्रदर्शन:वे लेखन में अतिरिक्त भार डालते हैं और सूचकांक रखरखाव की आवश्यकता होती है।
- डिज़ाइन:एक साफ ERD संचार में सहायता करता है, लेकिन एक घना ERD अत्यधिक सामान्यीकरण का संकेत दे सकता है।
- अनुकूलन:सूचकांकन, विभाजन और असामान्यीकरण विदेशी कुंजियों के प्रभाव को प्रबंधित करने के उपकरण हैं।
एप्लिकेशन के विशिष्ट लोड का विश्लेषण करके डिज़ाइनकार विदेशी कुंजियों के उचित घनत्व का निर्धारण कर सकते हैं। लक्ष्य एक स्कीमा है जो त्रुटियों को रोकने के लिए पर्याप्त मजबूत हो, लेकिन उच्च गति वाले डेटा प्रोसेसिंग को संभालने के लिए पर्याप्त लचीला हो।
प्रभावी डेटाबेस डिज़ाइन के लिए निरंतर निगरानी की आवश्यकता होती है। जैसे-जैसे डेटा पैटर्न बदलते हैं, विदेशी कुंजियों का प्रदर्शन प्रोफाइल बदल जाएगा। निरंतर निष्पादन योजनाओं और लॉक सांख्यिकी की समीक्षा सुनिश्चित करती है कि एंटिटी रिलेशनशिप डायग्राम समय के साथ प्रणाली के व्यवहार का सटीक प्रतिबिंब बना रहे।