











एक बड़े पैमाने वाले बैकएंड सिस्टम के डेटा आर्किटेक्चर को डिज़ाइन करना एक मूलभूत कार्य है जो पूरे एप्लिकेशन की लंबाई और स्थिरता को निर्धारित करता है। एंटिटी रिलेशनशिप डायग्राम, जिसे आमतौर पर ERD के रूप में संक्षिप्त किया जाता है, इस आर्किटेक्चर के लिए ब्लूप्रिंट के रूप में कार्य करता है। यह डेटा की संरचना को दृश्य रूप से नक्शा बनाता है, जिसमें विभिन्न जानकारी के टुकड़ों के बीच कैसे जुड़ना, संबंध बनाना और प्रणाली के भीतर बातचीत करना है, इसका वर्णन किया जाता है। एंटरप्राइज परिदृश्य में, जहां डेटा सुसंगतता, अखंडता और स्केलेबिलिटी महत्वपूर्ण हैं, स्थापित ERD मानकों का पालन करना केवल एक अच्छी प्रथा नहीं है; यह एक आवश्यकता है।
डेटा मॉडलिंग के लिए मानकीकृत दृष्टिकोण के बिना, बैकएंड सिस्टम को नाजुक होने का खतरा है। असंगत नामकरण पद्धतियां, अस्पष्ट संबंध और खराब नॉर्मलाइजेशन प्रदर्शन के बॉटलनेक, कठिन रखरखाव चक्रों और डेटा के विकृत होने के कारण बन सकते हैं। इस गाइड में जटिल एंटरप्राइज परिवेश के लिए उपयुक्त बलिया डेटाबेस स्कीमा बनाने के लिए आवश्यक महत्वपूर्ण मानकों और विधियों का अध्ययन किया जाएगा। हम मुख्य घटकों, नोटेशन प्रणालियों, नॉर्मलाइजेशन नियमों और नियंत्रण रणनीतियों का अध्ययन करेंगे जिनका उपयोग पेशेवर टीमें अपनी डेटा परतों को समय के साथ भी विश्वसनीय बनाए रखने के लिए करती हैं।
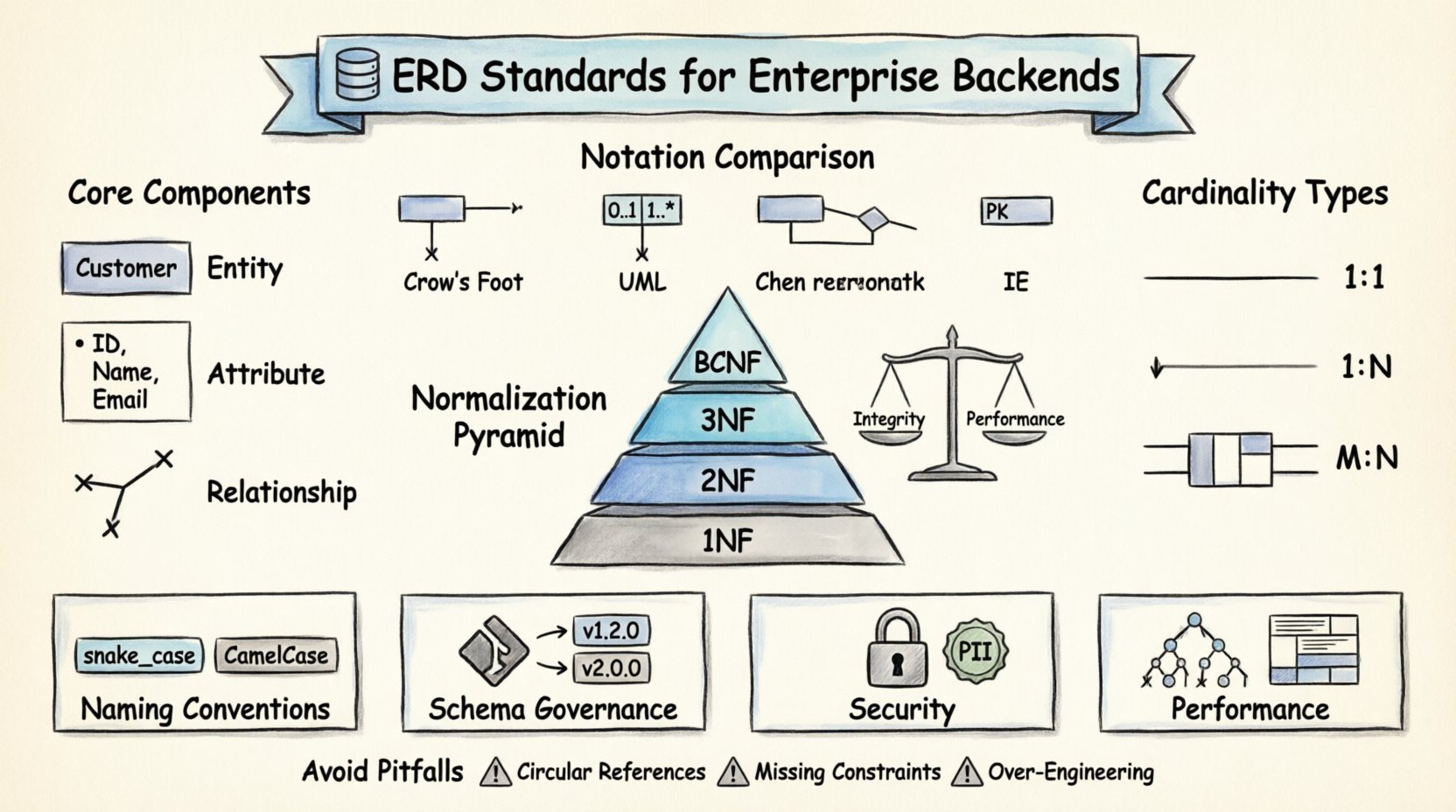
एंटरप्राइज ERD के मुख्य घटक 🧩
विशिष्ट मानकों में डूबने से पहले, एक ERD के निर्माण करने वाले मूल निर्माण तत्वों को समझना आवश्यक है। पेशेवर परिदृश्य में प्रत्येक आरेख तीन मुख्य तत्वों पर निर्भर करता है। इन तत्वों का सहयोग डेटा की तार्किक संरचना का वर्णन करता है।
- एंटिटीज: ये वास्तविक दुनिया की वस्तुओं या अवधारणाओं का प्रतिनिधित्व करते हैं जिनके बारे में डेटा संग्रहीत किया जाता है। बैकएंड संदर्भ में, एक एंटिटी अक्सर डेटाबेस टेबल के सीधे मैप होती है। उदाहरण के लिए ग्राहक, आदेश, या उत्पाद। एंटिटीज को स्पष्ट रूप से परिभाषित किया जाना चाहिए ताकि प्रत्येक रिकॉर्ड को एक अद्वितीय पहचान मिल सके।
- गुणधर्म: गुणधर्म एक एंटिटी के विशिष्ट गुण या विशेषताओं का वर्णन करते हैं। वे टेबल के कॉलम के समान होते हैं। एक ग्राहक एंटिटी के लिए, गुणधर्म में शामिल हो सकते हैं ग्राहकआईडी, पूर्णनाम, और ईमेलपता। गुणधर्मों के लिए डेटा प्रकारों को सही तरीके से परिभाषित करना डेटा अखंडता के लिए महत्वपूर्ण है।
- संबंध: संबंध यह निर्धारित करते हैं कि एंटिटीज एक दूसरे के साथ कैसे बातचीत करती हैं। वे टेबलों के बीच प्रतिबंधों और संबंधों को स्थापित करते हैं। उदाहरण के लिए, एक ही ग्राहक बहुत सारे आदेश। इस संबंध के कारण बैकएंड में आवश्यक फॉरेन की प्रतिबंधों और जॉइन लॉजिक को निर्धारित किया जाता है।
एंटरप्राइज-ग्रेड विकास में, इन घटकों को केवल अमूर्त अवधारणाएं नहीं माना जाता है; ये प्रश्न अनुकूलन, पहुंच नियंत्रण और डेटा स्थानांतरण रणनीतियों के आधार हैं। एक अच्छी तरह से दस्तावेजीकृत ERD डेवलपर्स को कोड की हर लाइन को जांचे बिना डेटा प्रवाह को समझने में सक्षम बनाता है।
नोटेशन मानक और दृश्य परंपराएँ 📐
ERD बनाने के लिए कोई एकल सार्वभौमिक सिंटैक्स नहीं है, लेकिन विभिन्न टीमों के बीच स्पष्टता और संगतता सुनिश्चित करने वाले व्यापक रूप से स्वीकृत मानक हैं। एक नोटेशन चुनना और उस पर टिके रहना एक महत्वपूर्ण शासन निर्णय है।
चेन नोटेशन बनाम क्राउ के पैर
ऐतिहासिक रूप से, चेन नोटेशन मानक रहा है, जिसमें प्राथमिकता के लिए आयताकार आकृतियों का उपयोग किया जाता था और संबंधों के लिए हीरे के आकार का उपयोग किया जाता था। हालांकि यह स्पष्ट है, लेकिन आधुनिक सॉफ्टवेयर विकास उपकरणों में यह कम प्रचलित है। क्राउ के पैर नोटेशन कई कारणों से उद्योग के प्राथमिकता के रूप में बन गया है:
- कार्डिनैलिटी में स्पष्टता: यह विशिष्ट प्रतीकों (रेखाएँ, गोले और “पैर”) का उपयोग एक-एक, एक-बहुत, और बहुत-बहुत संबंधों को दृश्य रूप से दर्शाने के लिए करता है।
- उपकरण समर्थन: अधिकांश आधुनिक डेटाबेस डिजाइन उपकरण और रिवर्स इंजीनियरिंग उपकरण बनाए गए क्राउ के पैर या यूएमएल-आधारित प्रतीकों का स्वाभाविक रूप से समर्थन करते हैं।
- पठनीयता: जटिल, एक-दूसरे से जुड़े स्कीमा के साथ काम करते समय यह आम तौर पर अधिक संक्षिप्त और पढ़ने में आसान होता है।
नोटेशन प्रणालियों की तुलना
| नोटेशन शैली | प्राथमिकता का प्रतिनिधित्व | संबंध का प्रतिनिधित्व | सर्वोत्तम उपयोग केस |
|---|---|---|---|
| क्राउ के पैर | आयत | प्रतीकों वाली रेखाएँ (क्राउ के पैर, गोला, रेखा) | संबंधात्मक डेटाबेस डिजाइन |
| यूएमएल क्लास डायग्राम | कम्पार्टमेंट वाला क्लास बॉक्स | गुणांकों वाली तीर (0..1, 1..*) | वस्तु-आधारित मॉडलिंग |
| चेन | आयत | प्राथमिकताओं को जोड़ने वाला हीरे का आकार | शैक्षणिक/सैद्धांतिक मॉडल |
| आईई (सूचना इंजीनियरिंग) | विशेषताओं वाला आयत | प्राथमिक कुंजी संकेतों वाली रेखाएँ | पुराने प्रणाली दस्तावेज़ीकरण |
कॉर्पोरेट बैकएंड के लिए, क्राउ के पैर नोटेशन को आमतौर पर सिफारिश की जाती है क्योंकि इसका सीधा मैपिंग संबंधात्मक प्रतिबंधों से होता है। इससे विकासकर्ताओं द्वारा कार्यान्वयन के दौरान आरेख के अर्थ को समझने में अस्पष्टता कम होती है।
नॉर्मलाइज़ेशन: डेटा अखंडता सुनिश्चित करना 🔄
नॉर्मलाइज़ेशन डेटाबेस में डेटा को व्यवस्थित करने की प्रक्रिया है ताकि अतिरिक्तता कम की जा सके और डेटा अखंडता में सुधार किया जा सके। आधुनिक प्रणालियाँ कभी-कभी प्रदर्शन के लिए नॉर्मलाइज़ेशन को वापस ले लेती हैं, लेकिन एक ठोस प्रारंभिक स्कीमा डिज़ाइन करने के लिए नॉर्मलाइज़ेशन नियमों को समझना आवश्यक है।
नॉर्मल फॉर्म्स
- पहला नॉर्मल रूप (1NF): प्रत्येक कॉलम में परमाणु मान होने चाहिए। एक ही सेल में मानों की सूची की अनुमति नहीं है। इससे सुनिश्चित होता है कि प्रत्येक पंक्ति और कॉलम के प्रतिच्छेदन में एक एकल, अविभाज्य डेटा का हिस्सा होता है।
- दूसरा नॉर्मल रूप (2NF): तालिका को 1NF में होना चाहिए, और सभी गैर-की विशेषताओं को मुख्य कुंजी पर पूरी तरह निर्भर होना चाहिए। इससे आंशिक निर्भरता को रोका जाता है जहां एक कॉलम केवल संयुक्त कुंजी के केवल एक हिस्से पर निर्भर होता है।
- तीसरा नॉर्मल रूप (3NF): तालिका को 2NF में होना चाहिए, और कोई भी संचारी निर्भरता नहीं होनी चाहिए। गैर-की विशेषताओं को अन्य गैर-की विशेषताओं पर निर्भर नहीं होना चाहिए। उदाहरण के लिए, यदि शहर पर निर्भर है पिन कोड पर निर्भर है पिन कोड पर निर्भर है आईडी, शहर को अलग तालिका में स्थानांतरित किया जाना चाहिए।
- बॉयस-कॉड नॉर्मल फॉर्म (BCNF): 3NF का कठोर रूप। इसमें यह आवश्यकता है कि प्रत्येक कार्यात्मक निर्भरता X → Y के लिए, X एक सुपरकी होनी चाहिए। इससे 3NF में कुछ विशेष स्थितियों को हैंडल किया जाता है जहां एक निर्धारक एक उम्मीदवार कुंजी है लेकिन मुख्य कुंजी नहीं है।
नॉर्मलाइज़ेशन व्यापार लाभ-हानि
| स्तर | लाभ | लागत |
|---|---|---|
| उच्च नॉर्मलाइज़ेशन (3NF/BCNF) | न्यूनतम अतिरिक्तता, उच्च अखंडता | प्रश्नों के लिए अधिक जॉइन की आवश्यकता होती है |
| कम सामान्यीकरण (असामान्यीकृत) | तेज पठन प्रदर्शन | डेटा असंगति का उच्च जोखिम |
एंटरप्राइज सिस्टम अक्सर अपने लेनदेन योजनाओं में 3NF का लक्ष्य रखते हैं। जब पठन प्रदर्शन एक बाधा बन जाता है, तो सामान्यीकरण को निश्चित दृश्यों या रिपोर्टिंग तालिकाओं पर चयनात्मक रूप से लागू किया जाता है, बल्कि मूल लेनदेन योजना के बजाय।
नामकरण नियम और योजना स्वच्छता 🏷️
रखरखाव के लिए एक संगत नामकरण पद्धति बहुत महत्वपूर्ण है। जब कई टीमें एक ही बैकएंड पर काम करती हैं, तो नामकरण में अस्पष्टता त्रुटियों का कारण बनती है। एक मानक को दस्तावेज़ित किया जाना चाहिए और लिंटिंग टूल्स या योजना सत्यापन स्क्रिप्ट्स के माध्यम से बल दिया जाना चाहिए।
तालिका नामकरण नियम
- बहुवचन बनाम एकवचन: इस पर विवाद है, लेकिन संगतता महत्वपूर्ण है। बहुवचन नाम (उदाहरण के लिए, उपयोगकर्ता, आदेश) अक्सर अंग्रेजी वाक्यों में बेहतर पढ़ते हैं। एकवचन नाम (उदाहरण के लिए, उपयोगकर्ता, आदेश) अक्सर ऑब्जेक्ट-ओरिएंटेड संदर्भ में पसंद किए जाते हैं। एक चुनें और इसे सार्वभौमिक रूप से लागू करें।
- अंडरस्कोर बनाम कैमलकेस: अंडरस्कोर (स्नेक_केस) SQL पहचानकर्ताओं के लिए मानक है। कैमलकेस (कैमलकेस) एप्लिकेशन कोड में सामान्य है। सुनिश्चित करें कि डेटाबेस लेयर और एप्लिकेशन लेयर अनुवाद रणनीति पर सहमत हैं।
- आरक्षित कीवर्ड्स से बचें: कभी भी आरक्षित डेटाबेस कीवर्ड्स का उपयोग करके किसी तालिका या कॉलम का नाम न रखें (उदाहरण के लिए, समूह, चुनें, आदेश). यह क्वेरी जनरेशन के दौरान सिंटैक्स त्रुटियों को रोकता है।
- मेटाडेटा के लिए प्रीफिक्स: प्रीफिक्स का उपयोग करें जैसे _audit, _log, या _temp सहायक तालिकाओं को मुख्य व्यापारिक एंटिटी से अलग करने के लिए।
कॉलम नामकरण नियम
- विदेशी कुंजियाँ: संबंध को स्पष्ट रूप से इंगित करें। यदि कोई कॉलम उपयोगकर्ता तालिका को संदर्भित करता है, तो इसका नाम रखें उपयोगकर्ता_आईडी बजाय इसके आईडी या एफके_उपयोगकर्ता.
- बूलियन फ्लैग्स: प्रीफिक्स का उपयोग करें जैसे है_ या है_। उदाहरण के लिए, है_सक्रिय या है_सदस्यता.
- तारीख़ और समय के फ़ील्ड: सीमा निर्दिष्ट करें। उपयोग करें बनाए गए के समय या अद्यतन किए गए के समय सामान्य के बजाय तारीख़ या समय.
संबंध और कार्डिनैलिटी 🔄
कार्डिनैलिटी को समझना एक कार्यरत डेटाबेस और एक खराब डेटाबेस के बीच का अंतर है। कार्डिनैलिटी एक एंटिटी के उन उदाहरणों की निर्दिष्ट संख्या को परिभाषित करती है जो दूसरी एंटिटी के प्रत्येक उदाहरण के साथ जुड़ सकते हैं या जुड़ने चाहिए।
संबंधों के प्रकार
- एक-से-एक (1:1): एंटिटी A का एक उदाहरण एंटिटी B के ठीक एक उदाहरण के साथ संबंधित होता है। यह मूल व्यावसायिक तर्क में दुर्लभ है लेकिन सुरक्षा या कॉन्फ़िगरेशन डेटा के लिए सामान्य है। उदाहरण: एक उपयोगकर्ता के पास एक है प्रोफ़ाइल.
- एक-से-बहुत (1:N): एंटिटी A का एक उदाहरण एंटिटी B के कई उदाहरणों के साथ संबंधित होता है। यह सबसे आम संबंध है। उदाहरण: एक विभाग के पास बहुत सारे हैं कर्मचारी.
- बहुत-से-बहुत (M:N): एंटिटी A के कई उदाहरण एंटिटी B के कई उदाहरणों के साथ संबंधित होते हैं। इसके लिए एक जंक्शन टेबल (सह-एंटिटी) की आवश्यकता होती है। उदाहरण: छात्र और पाठ्यक्रम.
वैकल्पिकता और सीमाएँ
कार्डिनैलिटी पूरी कहानी नहीं बताती है; वैकल्पिकता बताती है। इसका मतलब है कि संबंध अनिवार्य है या वैकल्पिक।
- अनिवार्य (अनिवार्य भागीदारी): एक एंटिटी उदाहरण को जुड़ना चाहिए दूसरे के साथ जुड़ा हुआ हो। उदाहरण के लिए, एक आदेश को जुड़ना चाहिए एक ग्राहक.
- वैकल्पिक (वैकल्पिक भागीदारी): एक एंटिटी उदाहरण बिना संबंध के अस्तित्व में रह सकता है। उदाहरण के लिए, एक अस्तित्व में रह सकता है। उदाहरण के लिए, एक उत्पाद बिना किसी आदेश रिकॉर्ड के बिना अस्तित्व में रह सकता है।
सीमाओं (NOT NULL, विदेशी कुंजियाँ) का उपयोग करके डेटाबेस स्तर पर इन नियमों को लागू करना एप्लिकेशन कोड में लागू करने से बहुत अधिक विश्वसनीय है। यह डेटा विचलन से बचाता है और यह सुनिश्चित करता है कि स्कीमा सच्चाई का स्रोत बना रहे।
स्कीमा शासन और संस्करण नियंत्रण 📜
कॉर्पोरेट वातावरण में, डेटाबेस स्कीमा कोड है। इसे संस्करण बनाना, समीक्षा करना और एप्लिकेशन स्रोत कोड के समान दृढ़ता के साथ प्रबंधित करना आवश्यक है। ईआरडी एक स्थिर दस्तावेज नहीं है; व्यवसाय की आवश्यकताओं में परिवर्तन के साथ यह विकसित होता रहता है।
माइग्रेशन रणनीतियाँ
- आगे की संगतता: बदलावों को पुराने डेटा को स्वीकार करने के लिए डिज़ाइन किया जाना चाहिए। तुरंत कॉलम को हटाने से बचें; बजाय उसे अप्रचलित चिह्नित करें।
- पीछे की संगतता: नए स्कीमा संस्करणों को मौजूदा क्वेरी को तोड़ने नहीं चाहिए। एप्लिकेशन परत से बदलावों को छिपाने के लिए व्यू का उपयोग करें।
- परमाणु बदलाव: प्रत्येक माइग्रेशन स्क्रिप्ट को एक एकल तार्किक बदलाव का प्रतिनिधित्व करना चाहिए। यदि कोई त्रुटि होती है तो रोलबैक करना आसान हो जाता है।
दस्तावेज़ीकरण रखरखाव
एक अद्यतन नहीं किया गया ERD एक दायित्व है। सुनिश्चित करें कि आरेडी उत्पादन प्रक्रिया स्वचालित है। आदर्श रूप से, ERD को स्कीमा परिभाषा फ़ाइलों (DML) से सीधे उत्पन्न किया जाना चाहिए ताकि दस्तावेज़ीकरण और वास्तविक डेटाबेस स्थिति के बीच विचलन न हो।
- हर कॉमिट पर ERD उत्पादन को स्वचालित करें।
- पुल अनुरोध प्रक्रिया में स्कीमा समीक्षा की आवश्यकता हो।
- एप्लिकेशन रिलीज़ के साथ संबंधित महत्वपूर्ण स्कीमा संस्करणों को टैग करें।
सुरक्षा और गोपनीयता के मामले 🔒
एंटरप्राइज़ बैकएंड संवेदनशील जानकारी का प्रबंधन करते हैं। ERD डिज़ाइन चरण में सुरक्षा और गोपनीयता की आवश्यकताओं को ध्यान में रखना आवश्यक है, विशेष रूप से व्यक्तिगत रूप से पहचाने जाने वाली जानकारी (PII) के संबंध में।
डेटा वर्गीकरण
- सार्वजनिक डेटा:वह जानकारी जो खुले तौर पर साझा की जा सकती है। कोई विशेष निपटान की आवश्यकता नहीं है।
- आंतरिक डेटा:केवल कर्मचारियों के लिए जानकारी। एक्सेस कंट्रोल सूचियां (ACLs) को ध्यान में रखना चाहिए।
- प्रतिबंधित डेटा:गोपनीय डेटा जैसे पासवर्ड, स्वास्थ्य रिकॉर्ड या वित्तीय विवरण। इन फ़ील्ड्स को स्थिर और प्रवाह में एन्क्रिप्शन की आवश्यकता होती है।
मास्किंग और अनामीकरण
ERD में उन फ़ील्ड्स को चिह्नित करें जिन्हें उत्पादन के अलावा पर्यावरणों में मास्क करने की आवश्यकता हो। इससे डेवलपर्स को समझने में मदद मिलती है कि परीक्षण के दौरान किन कॉलम को विशेष निपटारा करने की आवश्यकता है। चाहे आरेडी स्वयं सुरक्षा को बाध्य न करे, लेकिन यह सुरक्षा नीतियों के कार्यान्वयन को मार्गदर्शन करता है।
- स्पष्ट रूप से उन कॉलम की पहचान करें जिनमें PII हो।
- ऑडिट फ़ील्ड्स को परिभाषित करें (उदाहरण के लिए, अंतिम संशोधित द्वारा) डेटा को किसने प्राप्त किया या बदला इसका अनुसरण करने के लिए।
- सुनिश्चित करें कि विदेशी कुंजियां आ interनल आईडी को न उजागर करें जिन्हें संख्यांकित किया जा सकता है।
प्रदर्शन और स्केलेबिलिटी योजना 🚀
जबकि ERD संरचना पर केंद्रित है, इसे प्रदर्शन को भी ध्यान में रखना चाहिए। एक स्कीमा जो तार्किक रूप से सही है लेकिन भौतिक रूप से धीमी है, लोड के तहत विफल हो जाएगी।
इंडेक्सिंग रणनीति
ERD में परिभाषित संबंध निर्धारित करते हैं कि इंडेक्स कहां आवश्यक हैं। विदेशी कुंजियों को इंडेक्स करना चाहिए ताकि जॉइन और सीमा जांच तेजी से हो सके। हालांकि, अत्यधिक इंडेक्सिंग लेखन ऑपरेशन को धीमा कर सकती है।
- प्राथमिक कुंजियां: हमेशा इंडेक्स किया जाता है।
- विदेशी कुंजियां: जॉइन प्रदर्शन में सुधार के लिए हमेशा इंडेक्स किया जाता है।
- खोज कॉलम: जहां क्लॉज में अक्सर उपयोग किए जाने वाले कॉलम को इंडेक्स होना चाहिए।
विभाजन और शार्डिंग
विशाल डेटासेट्स के लिए, एरडी विभाजन रणनीतियों की ओर इशारा कर सकता है। यदि डेटा प्राकृतिक रूप से समूहित है (उदाहरण के लिए, क्षेत्र या तारीख), इसे स्कीमा डिजाइन में दर्शाया जाना चाहिए। इससे डेटाबेस को कई भौतिक नोड्स के बीच लोड वितरित करने की अनुमति मिलती है।
बचने के लिए सामान्य त्रुटियाँ ⚠️
यहां तक कि अनुभवी टीमें भी गलतियां करती हैं। विफलता के सामान्य पैटर्न को पहचानना एक लचीले सिस्टम के निर्माण में मदद करता है।
- चक्रीय संदर्भ: ऐसे संबंधों से बचें जहां एंटिटी A को B पर निर्भरता हो, और B को A पर निर्भरता हो, जिससे एक लूप बनता है जो डेटा के हटाने या अपडेट करने को जटिल बना देता है।
- अनुपस्थित सीमाएं: एप्लीकेशन कोड पर निर्भर रहना नियमों को लागू करने के लिए (उदाहरण के लिए, सुनिश्चित करना कि एक मूल्य सकारात्मक है) जोखिम भरा है। डेटाबेस में CHECK सीमाओं का उपयोग करें।
- अत्यधिक डिजाइन: हर संभावित भविष्य के सिनारियो को मॉडल न करें। वर्तमान आवश्यकताओं के लिए डिजाइन करें, जिसमें अनुकूलन के लिए पर्याप्त लचीलापन हो, लेकिन काल्पनिक उपयोग के मामलों के लिए टेबल बनाने से बचें।
- कड़े मान: लुकअप टेबल के बिना स्टेटस कोड को पूर्णांक के रूप में संग्रहीत करने से बचें। स्टेटस जैसे आदेश स्थिति के लिए संदर्भ टेबल का उपयोग करें ताकि स्पष्टता बनी रहे।
अपने वर्कफ्लो में मानकों को लागू करना 🛠️
इन मानकों को अपनाने के लिए संस्कृति में परिवर्तन की आवश्यकता होती है। बस एक आरेख बनाना पर्याप्त नहीं है; आरेख को विकास प्रक्रिया को आगे बढ़ाना चाहिए।
- पहले डिजाइन करें: किसी भी माइग्रेशन स्क्रिप्ट लिखने से पहले एरडी को अनुमोदित करने की आवश्यकता होती है।
- कोड समीक्षा: मानक कोड समीक्षा चेकलिस्ट में स्कीमा परिवर्तन शामिल करें।
- प्रशिक्षण: सुनिश्चित करें कि सभी बैकएंड इंजीनियर नॉर्मलाइजेशन और कार्डिनैलिटी अवधारणाओं को समझते हैं।
- उपकरण: सहयोग और संस्करण प्रबंधन को समर्थित करने वाले स्कीमा डिज़ाइन उपकरणों में निवेश करें।
सिस्टम आर्किटेक्चर के एक जीवंत, सांस लेते हुए घटक के रूप में एंटिटी रिलेशनशिप डायग्राम के साथ व्यवहार करके, एंटरप्राइज टीमें यह सुनिश्चित कर सकती हैं कि उनके डेटा लेयर लचीले बने रहें। डिज़ाइन चरण को मानकीकृत करने में लगाए गए प्रयास का लाभ तकनीकी दायित्व में कमी और सिस्टम विश्वसनीयता में सुधार के रूप में मिलता है। एक अच्छी तरह से संरचित डेटाबेस स्केलेबल एप्लिकेशनों के निर्माण के लिए आधार है।
जब आप अपने डेटा मॉडलिंग में स्पष्टता, सुसंगतता और अखंडता को प्राथमिकता देते हैं, तो आप विकास के लिए समर्थन करने वाली एक आधार तैयार करते हैं। यहां बताए गए मानक उस आधार के लिए एक ढांचा प्रदान करते हैं। उनका पालन करने से यह सुनिश्चित होता है कि आपका बैकएंड आपके संगठन के स्केल होने के साथ भी रखरखाव योग्य, सुरक्षित और कुशल बना रहे।