











डेटा मॉडलिंग आमतौर पर किसी भी सॉफ्टवेयर एप्लिकेशन की अदृश्य पृष्ठभूमि होती है। जबकि व्यापार तर्क को चलाने वाला कोड ध्यान केंद्रित करता है, उसके नीचे वाला स्कीमा प्रदर्शन, स्केलेबिलिटी और रखरखाव को निर्धारित करता है। कई जूनियर इंजीनियरों के लिए एंटिटी रिलेशनशिप डायग्राम (ERD) बॉक्स बनाने और लाइनें जोड़ने का एक सरल अभ्यास है। हालांकि, यह सरलता भ्रामक है। एक खराब ढंग से बनाया गया ERD एक ऋण बन जाता है जो समय के साथ बढ़ता जाता है, जिसके कारण जटिल क्वेरीज, डेटा अखंडता की समस्याएं और कठिन माइग्रेशन होते हैं।
यह गाइड छुपे हुए जटिलता के अंतराल का अध्ययन करता है। यह बताता है कि सैद्धांतिक ज्ञान और व्यावहारिक अनुप्रयोग के बीच कहां असंगति होती है। इन त्रुटियों को समझकर डेवलपर्स बुनियादी डायग्रामिंग से आगे बढ़कर वास्तविक आर्किटेक्चरल सोच की ओर बढ़ सकते हैं।
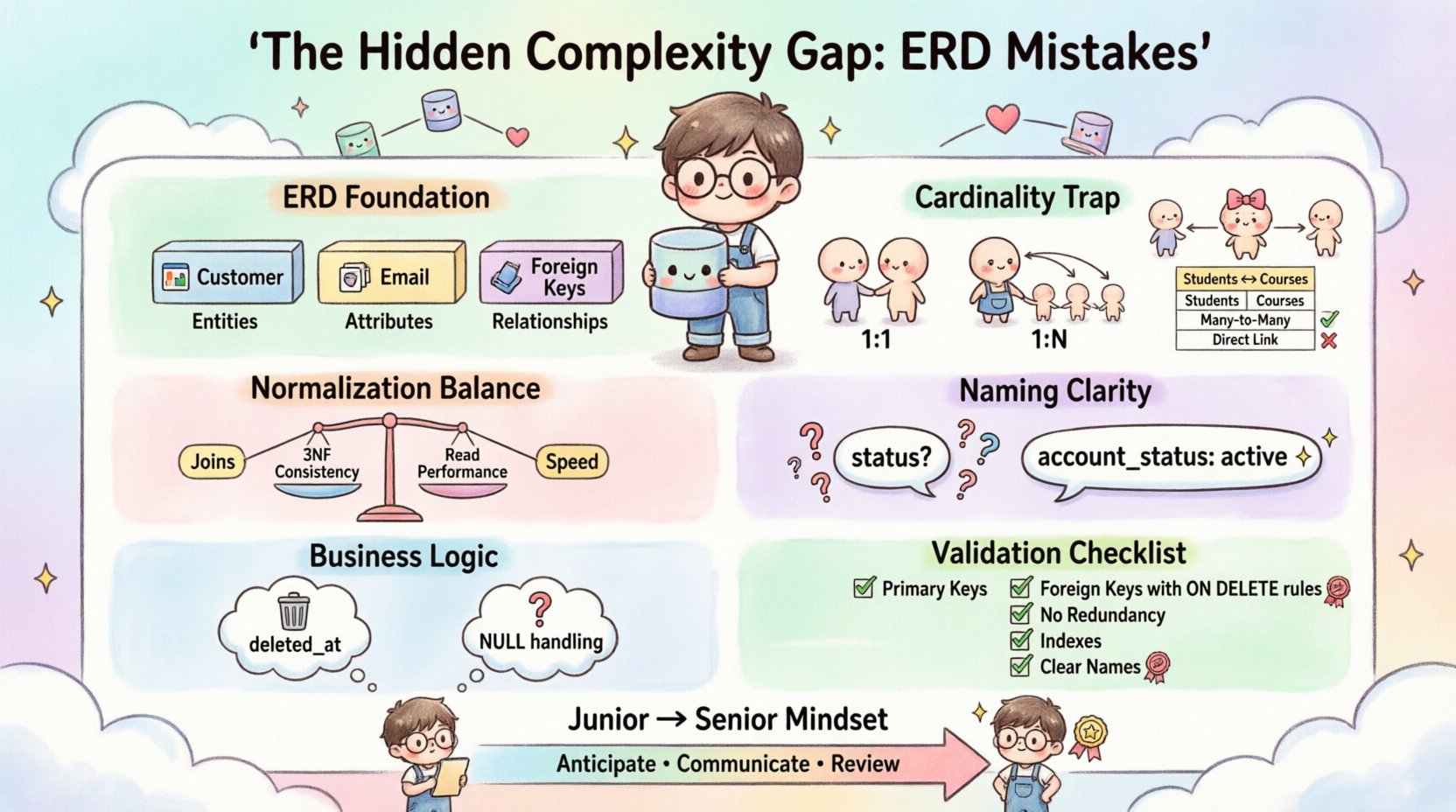
1. डेटा मॉडलिंग के आधार को समझना 🏗️
त्रुटियों में डूबने से पहले, यह आवश्यक है कि हम यह स्थापित करें कि ERD वास्तव में क्या प्रतिनिधित्व करता है। यह सिर्फ एक ड्राइंग नहीं है; यह एप्लिकेशन और स्टोरेज लेयर के बीच एक संविदा है। ERD एंटिटीज (टेबल), एट्रिब्यूट्स (कॉलम) और रिलेशनशिप्स (फॉरेन कीज) को दृश्यमान करता है।
जब कोई इंजीनियर इसे एक बार बनाए गए और भूल जाने वाले स्थिर अभिलेख के रूप में लेता है, तो वह डेटा की गतिशील प्रकृति को नजरअंदाज कर देता है। डेटा मॉडल व्यापार आवश्यकताओं के बदलने के साथ विकसित होते रहते हैं। एक जूनियर इंजीनियर तुरंत फीचर पर ध्यान केंद्रित कर सकता है, जैसे कि उपयोगकर्ता का नाम स्टोर करना, लेकिन उस उपयोगकर्ता के अन्य एंटिटीज जैसे ऑर्डर, सब्सक्रिप्शन या लॉग्स के साथ बातचीत करने के तरीके को नजरअंदाज कर देता है।
- एंटिटीज: ये वास्तविक दुनिया की वस्तुओं या अवधारणाओं का प्रतिनिधित्व करते हैं (जैसे: ग्राहक, उत्पाद, इन्वॉइस)।
- एट्रिब्यूट्स: ये एंटिटी को परिभाषित करने वाले गुण हैं (जैसे: ईमेल, मूल्य, तारीख)।
- रिलेशनशिप्स: ये एंटिटीज के बीच बातचीत के तरीके को परिभाषित करते हैं (जैसे: एक से बहुत, बहुत से बहुत)।
एक मजबूत मॉडल भविष्य के विकास को ध्यान में रखता है। यह यह अनुमान लगाता है कि एक ‘ग्राहक’ को ‘उपयोगकर्ता’ बनाया जा सकता है या एक ‘उत्पाद’ को विभिन्न रूपों की आवश्यकता हो सकती है। प्रारंभिक डायग्राम इन बदलावों को स्वीकार करने के लिए पर्याप्त लचीला होना चाहिए बिना पूरी तरह से पुनर्निर्माण के।
2. कार्डिनैलिटी का फंदा: संबंधों के गलत व्याख्या करना 🔄
कार्डिनैलिटी डेटाबेस डिजाइन में संरचनात्मक विफलता का सबसे आम कारण है। यह एंटिटी के उदाहरणों के बीच संख्यात्मक संबंध को परिभाषित करता है। इसकी गलत समझ से अक्षम भंडारण और जटिल जॉइन लॉजिक की समस्या उत्पन्न होती है।
आम कार्डिनैलिटी परिदृश्य
इंजीनियर अक्सर एज केस को ध्यान में रखे बिना सबसे आम संबंध को चुनते हैं। निम्नलिखित परिदृश्यों पर विचार करें जहां मान्यताएं त्रुटियों की ओर ले जाती हैं:
- एक से एक (1:1): अक्सर अत्यधिक उपयोग किया जाता है। यदि दो एंटिटीज के बीच 1:1 संबंध है, तो उन्हें आमतौर पर एक ही टेबल में मिलाया जाना चाहिए ताकि जॉइन ओवरहेड कम हो, बशर्ते कि सख्त सुरक्षा अलगाव की आवश्यकता न हो।
- एक से बहुत (1:N): सबसे आम संबंध। एक एकल पैरेंट रिकॉर्ड बहुत सारे चाइल्ड रिकॉर्ड से संबंधित होता है। फॉरेन की चाइल्ड तरफ स्थित होनी चाहिए।
- बहुत से बहुत (M:N): यहीं जटिलता का अंतराल बढ़ता है। एक मध्यवर्ती टेबल के बिना एक सीधे M:N संबंध को संबंधित मॉडल में भौतिक रूप से संभव नहीं है।
तालिका: कार्डिनैलिटी कार्यान्वयन की त्रुटियां
| परिदृश्य | गलत तरीका | सही तरीका |
|---|---|---|
| छात्र और कोर्स | छात्र टेबल में ‘कोर्सआईडी’ कॉलम जोड़ना | छात्र_कोर्स जंक्शन टेबल बनाना |
| आदेश और उत्पाद | आदेश तालिका में उत्पाद विवरण को सीधे एम्बेड करना | आदेश आइटम तालिका के माध्यम से लिंक करना |
| कर्मचारी और विभाग | एक जंक्शन तालिका के बिना एक कर्मचारी के कई विभागों में सदस्यता की अनुमति देना | मैपिंग संबंध को अलग करना |
जब इंजीनियर डेटा को दोहराकर एकल तालिका में बहु-से-बहु संबंध को बल देने की कोशिश करते हैं, तो वे अतिरेक लाते हैं। यदि एक उत्पाद की कीमत बदलती है, तो उस उत्पाद के प्रत्येक आदेश रिकॉर्ड में उसके अपडेट करने की आवश्यकता होती है जहां वह उत्पाद दिखाई देता है। इससे नॉर्मलाइजेशन सिद्धांतों का उल्लंघन होता है और रखरखाव के लिए भयानक समस्याएं उत्पन्न होती हैं।
3. नॉर्मलाइजेशन के भ्रम और वास्तविकता की जांच 📉
नॉर्मलाइजेशन एक मानक अवधारणा है जो शैक्षणिक संदर्भों में पढ़ाई जाती है। लक्ष्य डेटा अतिरेक को कम करना और अखंडता में सुधार करना है। हालांकि, नौसिखिया इंजीनियर अक्सर प्रदर्शन के व्यापारिक लाभ-हानि के बिना अत्यधिक नॉर्मलाइजेशन (5NF तक) करते हैं।
अत्यधिक नॉर्मलाइजेशन की जाल
एक अत्यधिक नॉर्मलाइज्ड स्कीमा डेटा को बहुत सी तालिकाओं में विभाजित करता है। यह सुनिश्चित करता है कि डेटा संगत रहे, लेकिन इससे एप्लिकेशन को अत्यधिक जॉइन करने के लिए मजबूर किया जाता है। प्रत्येक जॉइन कंप्यूटेशनल लागत बढ़ाता है। उच्च ट्रैफिक वाली प्रणालियों में, यह एक बॉटलनेक बन सकता है।
- 1NF (पहला सामान्य रूप):परमाणु मान। एक ही सेल में कोई सूची नहीं।
- 2NF (दूसरा सामान्य रूप):कोई आंशिक निर्भरता नहीं। सभी गैर-कुंजी विशेषताओं को पूर्ण मुख्य कुंजी पर निर्भर होना चाहिए।
- 3NF (तीसरा सामान्य रूप):कोई स्थानांतरित निर्भरता नहीं। विशेषताओं को अन्य गैर-कुंजी विशेषताओं पर निर्भर नहीं होना चाहिए।
एक सामान्य गलती यह मानना है कि 3NF हमेशा लक्ष्य होता है। कुछ मामलों में, डेनॉर्मलाइजेशन एक जानबूझकर डिजाइन चयन होता है। उदाहरण के लिए, आदेश तालिका पर सीधे “कुल आदेश राशि” संग्रहीत करने से आदेश को प्रदर्शित करने पर हर बार आइटम के योग की गणना करने से बचा जा सकता है। इससे लेखन प्रदर्शन के बदले पढ़ने के प्रदर्शन का विनिमय होता है।
तालिका: नॉर्मलाइजेशन बनाम डेनॉर्मलाइजेशन
| कारक | नॉर्मलाइज्ड (3NF) | डेनॉर्मलाइज्ड |
|---|---|---|
| डेटा अतिरेक | कम | उच्च |
| लेखन गति | तेज | धीमी |
| पढ़ने की गति | धीमी (अधिक जॉइन्स) | तेज़ |
| डेटा अखंडता | उच्च | निम्न (तर्क की आवश्यकता है) |
अनियमितता का निर्णय डेटा-आधारित होना चाहिए। इसे बिना कारण नहीं होने देना चाहिए। टेबलों को मिलाने से पहले � ingineers को क्वेरी प्रदर्शन का प्रोफाइलिंग करना चाहिए। संदर्भ के बिना नियमितता नियमों का अनबुद्ध अनुसरण ऐसे प्रणालियों के निर्माण के लिए लीड करता है जो संगत हैं लेकिन धीमी हैं।
4. नामकरण प्रणाली और अर्थपूर्ण स्पष्टता 🏷️
स्कीमा नाम डेटाबेस की शब्दावली हैं। यदि शब्दावली अस्पष्ट है, तो प्रणाली भविष्य के विकासकर्ताओं के लिए अस्पष्ट हो जाती है। यह एक आम समस्या है जहां तकनीकी सटीकता को संक्षिप्तता के लिए त्याग दिया जाता है।
एक फ़ील्ड जिसका नाम है स्थिति खतरनाक है। इसका क्या मतलब है? क्या यह एक सक्रिय खाता है? एक लंबित भुगतान? एक हटाया गया रिकॉर्ड? संदर्भ के बिना, अर्थ खो जाता है। इसी तरह, टेबल के लिए बहुवचन नामों का उपयोग (उदाहरण के लिए, उपयोगकर्ता) के बजाय एकवचन (उदाहरण के लिए, उपयोगकर्ता) असंगति पैदा करता है।
- संगतता:यदि एक टेबल का उपयोग करता है
स्नेक_केस, सभी को उपयोग करना चाहिएस्नेक_केस. - वर्णनात्मकता:डेटा का वर्णन करने वाले नामों का उपयोग करें, केवल प्रारूप के बजाय। सामान्य शब्दों जैसे
टेबल1याडेटा. - संदर्भ:यदि अस्पष्टता हो, तो संबंध कुंजी में एंटिटी का नाम शामिल करें। उपयोग करें
उपयोगकर्ता_आईडीकेवलआईडीजब संभव हो, तब
एक प्रणाली के संदर्भ में विचार करें जिसमें उपयोगकर्ताओं के कई प्रकार हैं: प्रशासक, ग्राहक और विक्रेता। एक एकल तालिका जिसका नाम है उपयोगकर्ता में एक भूमिका कॉलम हो सकता है। यह एक “देवता तालिका” है। एक बेहतर दृष्टिकोण अलग-अलग तालिकाओं या स्पष्ट विरासत रणनीति का उपयोग करना है। जब अनुमतियाँ और डेटा पहुँच नियम भूमिकाओं के बीच बहुत अलग हो जाते हैं, तो यह अंतर महत्वपूर्ण हो जाता है।
5. तकनीकी डिजाइन में व्यापार तर्क को नजरअंदाज करना 🧠
जूनियर और सीनियर � ingineers के बीच सबसे बड़ा अंतर व्यापार तर्क की समझ है। एक जूनियर इंजीनियर एक स्कीमा बना सकता है जो वर्तमान कोड आवश्यकताओं के लिए पूरी तरह से फिट होता है, लेकिन जब व्यापार नियम बदलते हैं तो वह विफल हो जाता है।
“सॉफ्ट डिलीट” की गलत समझ
बहुत से विकासकर्ता सिर्फ एक हटाया_गया_समय कॉलम एक तालिका में जोड़ देते हैं। यह सरल मामलों के लिए काम करता है। हालांकि, यदि एक उपयोगकर्ता को हटा दिया जाता है, तो क्या उनके संबंधित लॉग हटाए जाने चाहिए? क्या उनके वित्तीय रिकॉर्ड ऑडिट संगतता के लिए बने रहने चाहिए? एरडी इन सीमाओं को सीमाओं और ट्रिगर्स के माध्यम से दर्शाना चाहिए, केवल एप्लीकेशन कोड के माध्यम से नहीं।
“नॉल” समस्या
NULL मानों को अनुमति देना अक्सर छिपी हुई जटिलता का कारण बनता है। कुछ मामलों में, NULL एक खाली स्ट्रिंग या शून्य से सामान्य रूप से अलग होता है। यदि कोई फ़ील्ड वैकल्पिक है, तो एरडी को इसका स्पष्ट रूप से इंगित करना चाहिए। हालांकि, तर्क नियंत्रण के लिए NULL के आधार पर निर्भर रहने की सलाह नहीं दी जाती है।
- संदर्भात्मक अखंडता: विदेशी कुंजियाँ आदर्श रूप से NULL नहीं होनी चाहिए, जब तक कि संबंध वास्तव में वैकल्पिक नहीं है।
- गणनाएँ: NULL मान गणनाओं के माध्यम से फैलते हैं, जिसके परिणामस्वरूप NULL परिणाम आते हैं। इससे एग्रीगेशन क्वेरीज़ टूट सकती हैं।
- इंडेक्स: इंडेक्स में NULL का निपटान डेटाबेस इंजन पर निर्भर करता है, जिससे क्वेरी प्रदर्शन प्रभावित हो सकता है।
6. खराब डिजाइन का रखरखाव बोझ 🔧
तकनीकी उधार केवल धीमे कोड के बारे में नहीं है; यह संरचनात्मक कठोरता के बारे में है। खराब डिजाइन किए गए एरडी बदलाव को दर्दनाक बना देता है। जब एक नया आवश्यकता आती है, जैसे कि “बिलिंग पता” को “शिपिंग पता” से अलग करके जोड़ना, तो इंजीनियर को मूल्यांकन करना होता है कि वर्तमान स्कीमा इसका समर्थन करता है या नहीं।
माइग्रेशन के रातोंरात भयानक अनुभव
लाखों रिकॉर्ड वाले उत्पादन डेटाबेस के स्कीमा में बदलाव करने के लिए सावधानीपूर्वक योजना बनाने की आवश्यकता होती है। यदि एरडी को माइग्रेशन के विचार से डिजाइन नहीं किया गया था, तो कॉलम प्रकार बदलना या एक तालिका को बांटना सिस्टम को घंटों तक लॉक कर सकता है। इस बंदी के कारण राजस्व और उपयोगकर्ता विश्वास प्रभावित होता है।
इसके निवारण के लिए रणनीतियाँ शामिल हैं:
- स्कीमा के लिए संस्करण नियंत्रण: डेटाबेस संरचना को एप्लीकेशन कोड की तरह लें।
- पीछे की ओर संगतता: उन्हें हटाने से पहले कॉलम जोड़ें। माइग्रेशन पूरी होने तक पुराने कॉलम को बनाए रखें।
- दस्तावेज़ीकरण: ईआरडी को सत्य का स्रोत होना चाहिए। यदि यह डेटाबेस से मेल नहीं खाता है, तो डेटाबेस गलत है।
7. ईआरडी सत्यापन के लिए व्यावहारिक चेकलिस्ट ✅
एक ठोस डिज़ाइन सुनिश्चित करने के लिए, इंजीनियरों को आरेख को अंतिम रूप देने से पहले एक सत्यापन चेकलिस्ट को चलाना चाहिए। इस प्रक्रिया को लागू करने से पहले तार्किक त्रुटियों को पकड़ने में मदद मिलती है।
अनुप्रयोग से पहले सत्यापन
| जांच | प्रश्न | उत्तीर्णता मानदंड |
|---|---|---|
| प्राथमिक कुंजियाँ | क्या प्रत्येक तालिका का एक अद्वितीय पहचानकर्ता है? | हाँ, स्वतः वृद्धि या यूआईडी |
| विदेशी कुंजियाँ | क्या संबंध स्पष्ट रूप से परिभाषित हैं? | हाँ, ON DELETE/UPDATE नियम के साथ |
| आवर्धन | क्या कोई डेटा एक से अधिक स्थानों पर संग्रहीत है? | नहीं, यदि अनियमितता जानबूझकर नहीं है |
| स्केलेबिलिटी | क्या इसमें वर्तमान डेटा आयतन के 10 गुना को संभालने में सक्षम है? | विदेशी कुंजियों पर इंडेक्स मौजूद हैं |
| पठनीयता | क्या एक नए भर्ती को 5 मिनट में प्रवाह समझने में सक्षम है? | स्पष्ट नामकरण प्रथाएँ |
8. उपकरण बनाम अवधारणाएँ 🛠️
किसी विशिष्ट उपकरण की सुविधाओं पर भरोसा करके डिज़ाइन समस्याओं को हल करना आसान है। हालांकि, उपकरण अवधारणा की तुलना में दूसरे स्थान पर है। चाहे विज़ुअल मॉडलिंग उपकरण का उपयोग कर रहे हों या सीधे एसक्यूएल स्क्रिप्ट लिख रहे हों, मूल तर्क एक ही रहता है।
कुछ इंजीनियर ऐसे आरेख बनाते हैं जो दृश्य रूप से पूर्ण लगते हैं लेकिन लक्षित डेटाबेस में व्याकरणिक रूप से असंभव हैं। उदाहरण के लिए, कुछ उपकरण दृश्य परत में चक्रीय निर्भरता की अनुमति देते हैं, जबकि डेटाबेस इंजन उन्हें अस्वीकार कर देगा। ध्यान केंद्रित ड्रॉइंग इंटरफेस के बजाय संबंधात्मक अखंडता नियमों पर रहना चाहिए।
- दृश्य सुसंगतता: संबंधों के लिए मानक प्रतीकों का उपयोग करें (क्राउ के फुट नोटेशन)।
- सत्यापन: सीमाओं की पुष्टि करने के लिए स्कीमा को एक परीक्षण डेटाबेस के खिलाफ चलाएं।
- सहयोग: व्यावसायिक क्षेत्र को समझने वाले स्टेकहोल्डर्स के साथ आरेख की समीक्षा करें, केवल तकनीकी सहकर्मियों के बजाय।
9. वास्तविक दुनिया के असफलता के परिदृश्य ⚠️
अमूर्त अवधारणाओं को समझना एक बात है; उन्हें व्यवहार में असफल होते देखना दूसरी बात है। नीचे आम परिदृश्य हैं जहां खराब ईआरडी डिजाइन भौतिक समस्याओं के कारण होता है।
परिदृश्य ए: अनंत लूप
एक विकासकर्ता के बीच एक संबंध बनाता हैउपयोगकर्ता औरटीमेंजहां एक उपयोगकर्ता एक टीम से संबंधित है, और एक टीम एक उपयोगकर्ता द्वारा नेतृत्व की जाती है। यदि विदेशी कुंजी उसी तालिका की ओर इशारा करती है बिना स्पष्ट मूल के, तो इन्सर्ट करते समय चक्रीय संदर्भ त्रुटियां होती हैं। ईआरडी को स्पष्ट रूप से “सदस्य” और “नेता” संबंधों के बीच अंतर करना चाहिए।
परिदृश्य बी: चुपचाप डेटा हानि
एकआदेशतालिका एक को संदर्भित करती हैउत्पादतालिका। तालिका केON DELETEप्रतिबंध को सेट किया गया हैकैस्केड। जब कोई उत्पाद कैटलॉग से हटाया जाता है, तो सभी संबंधित आदेशों को हटा दिया जाता है। इससे ऐतिहासिक बिक्री डेटा नष्ट हो जाता है। ईआरडी को स्पष्ट रूप से संदर्भात्मक क्रिया को परिभाषित करना चाहिएप्रतिबंधित याNULL सेट करें व्यावसायिक आवश्यकता के अनुसार।
परिदृश्य सी: धीमी खोज
एक तालिका बनाई जाती है जिसमें एकनामकॉलम। इंजीनियर इस तालिका को नाम से उपयोगकर्ताओं को खोजने के लिए अक्सर प्रश्न करते हैं। डिजाइन चरण में इंडेक्स को परिभाषित किए बिना, डेटाबेस पूरी तालिका की स्कैनिंग करता है। ईआरडी को यह दर्शाना चाहिए कि कौन से कॉलम खोज-भारी हैं और इंडेक्सिंग की आवश्यकता है।
10. जूनियर से सीनियर माइंडसेट में विकास 🚀
संक्रमण में फोकस को “क्या यह काम करता है?” से “क्या यह स्केल होता है?” और “क्या यह बनाए रखने योग्य है?” में बदलना शामिल है।
- पूर्वानुमान: उद्योग के रुझानों के आधार पर भविष्य की आवश्यकताओं का अनुमान लगाएं।
- संचार: तकनीकी सीमाओं को व्यापारिक जोखिमों में बदलें।
- समीक्षा: कभी भी समीक्षा के बिना किसी आरेख को सही मानने की गलती न करें।
जूनियर इंजीनियर अक्सर अकेले काम करते हैं। सीनियर इंजीनियर सहयोग करते हैं। एरडी एक संचार उपकरण है। यह डेवलपर्स, प्रोडक्ट मैनेजर्स और हितधारकों के बीच के अंतर को पार करता है। यदि आरेख भ्रमित है, तो अपेक्षाएं गलत रूप से संरेखित होंगी।
डेटा अखंडता पर अंतिम विचार 🎯
डेटाबेस स्कीमा बनाना एक बार का कार्य नहीं है; यह एक निरंतर अनुशासन है। जटिलता का अंतर इसलिए है क्योंकि जोखिम बहुत अधिक है। एप्लिकेशन कोड में गलती को हॉट-फिक्स किया जा सकता है। डेटा मॉडल में गलती के लिए अक्सर माइग्रेशन, डेटा साफ करना और बंदी होना आवश्यक होता है।
सख्त मॉडलिंग सिद्धांतों का पालन करने, कार्डिनैलिटी को गहराई से समझने और सुविधा की तुलना में व्यापारिक तर्क को प्राथमिकता देने से इंजीनियर अंतर को कम कर सकते हैं। लक्ष्य पूर्ण आरेख बनाना नहीं है, बल्कि ऐसा आधार बनाना है जो सॉफ्टवेयर के विकास का समर्थन करे। डेटा एक एप्लिकेशन की सबसे मूल्यवान संपत्ति है। इसकी संरचना की रक्षा करना बिल्ड प्रक्रिया में शामिल हर इंजीनियर की जिम्मेदारी है।
अपने आरेखों की समीक्षा करने के लिए समय निकालें। हर संबंध को प्रश्न चिन्हित करें। हर सीमा की पुष्टि करें। डिजाइन चरण में निवेश किया गया समय रखरखाव चरण में महीनों के प्रयास को बचाता है।